
Python의 multiprocessing의 process 개수 증가에 따른 rasterio 래스터 처리 속도 비교
본 포스트는 multiprocessing을 이용한 다중프로세스 기법을 이용하여 block-by-block 방식으로 래스터를 처리할 때, 프로세스 개수의 증가가에 따른 수행 시간 변화를 측정한 결과를 제시합니다.
복수 개의 대용량 래스터를 읽고 계산하고 저장하는 일련의 과정은 많은 컴퓨팅 자원을 필요로합니다. CPU 연산 능력, Memory 용량 및 대역폭, Disk 입출력 성능 등 전체 성능에 영항이 있을 많은 지점이 존재합니다. CPU 연산 능력이 아무리 좋아도 파일 읽기 속도가 느리다면 CPU는 제 역할을 하지 못할 것입니다. 메모리 대역폭 또한 속도에 중요한 영향을 줍니다. 래스터 자료 처리에 있어 CUDA/OpenCL 등의 기술을 이용할 경우 가장 문제가 되는 부분도 메모리 대역폭 문제입니다. 하드웨어 성능이 충분하고 CPU의 모든 코어를 쏟어 붓는다 해도, 연산 복잡도가 낮으면 다중프로세스/다중스레드에 발생하는 오버헤드로 인해 오히려 단일프로세스/단일스레드로 처리하는 것이 더 좋은 결과를 보일 수도 있습니다. 특정 CPU, Memory, Disk 조합에서 어느 정도의 연산량에 어느 정도의 프로세스 혹은 스레드를 할당해야 하는지 잘 모르겠습니다. 단순히 여기에서는 ‘어떠한 연산도 최소 이정도 연산은 한다’라고 추측되는 정도의 연산(산술 평균)을 적용하여 보았습니다.
3개의 래스터에 대한 산술 평균을 구한 후 1개의 래스터에 저장하는 프로그램을, multiprocessing을 이용하여 프로세스 개수를 1개에서 부터 8개까지 증가시켜 가면서 속도를 측정해 보았습니다. 가장 먼저 N개의 프로세스가 main_work 함수에 진입하여, 각자의 컨텍스트에 rasterio.open 을 수행한 결과 raster_ary를 취합니다. 그 후 블록 개수 만큼(블록의 개수는 첫 번째 래스터의 block_windows을 통해 얻음) process_block_window을 반복 호출합니다. 호출 인자로서 블록의 위치 xy와 블록의 영역 window가 전달됩니다. 코드 참조
import multiprocessing
import rasterio
raster_files = [
'./dem.30m.1.tiff',
'./dem.30m.2.tiff',
'./dem.30m.3.tiff',
]
raster_ary = None
def main_worker():
global raster_ary
raster_ary = [rasterio.open(x) for x in raster_files]
def process_block_window(args):
xy, window = args
x = 0
for raster in raster_ary:
x += raster.read(1, masked=True)
x /= len(raster_ary)
return x, window
processes = 2
pool = multiprocessing.Pool(processes, main_worker)
first_raster = rasterio.open(raster_files[0])
profile = first_raster.profile.copy()
block_windows = list(first_raster.block_windows())
out_rast = rasterio.open('output.tiff', 'w', **profile)
for data, window in pool.imap_unordered(process_block_window, block_windows):
out_rast.write(data, window=window)
out_rast.close()
측정 결과는 예상외로 신통치 않았습니다. 프로세스를 8배 증가 시켰음에도 속도 향상 비율은 1.4배에 그쳤습니다.
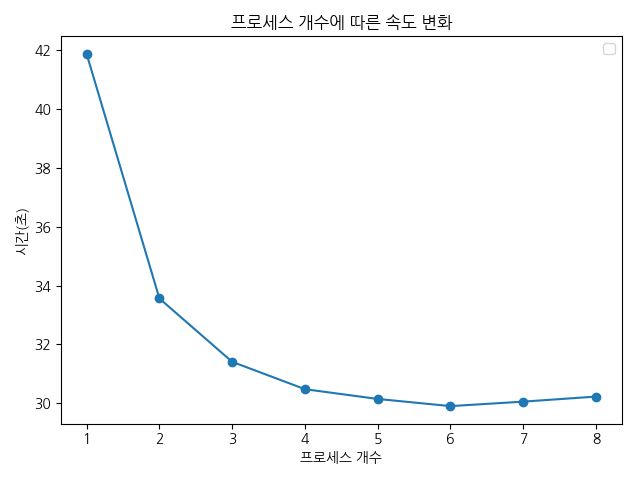
좀 더 살펴보니 이와 같은 결과가 나온 이유는 복수개의 래스터를 블록별로 읽기 및 계산은 병렬로 처리되지만,
계산된 래스터를 파일로 저장 할 때에는(상기 제시된 코드의 out_rast.write(data, window=window) 부분) 직렬로 처리되기
때문입니다.
GDAL에서 사용하는 GeoTIFF는 읽기에 대해서는 thread-save이지만,
쓰기에 대해서는 그렇지 않습니다.
더욱이 래스터 파일을 GeoTIFF 형식으로 저장할 때 deflate 압축
기법을 사용하는데 이것으로 인해 많은 연산이 요구됩니다. 따라서 저장하는 부분의 병목 지점을 보완해야 합니다.
사실 이것을 위해 선택지는 별로 없습니다. 적당한 타협은 GDAL_NUM_THREADS 를 사용하여 GeoTIFF 저장시 libtiff 가
멀티스레드를 이용하도록 하는 것입니다. GDAL_NUM_THREADS=ALL_CPUS 를 이용하여 모든 CPU를 이용하도록 하거나, 스래드
개수를 정수로 지정하면 됩니다.
4 코어를 이용하여 테스트 해 본 결과 아래와 같았습니다.
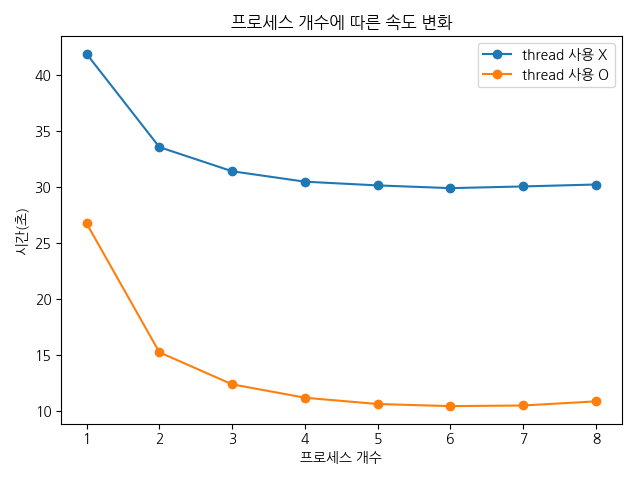
스레드를 사용한 경우와 사용하지 않은 경우의 시간 차이가 프로세스 개수에 상관 없이 20초 정도로 일정합니다. 프로세스를 더 투입해도 스레드 사용 여부에 따라 얻는 이득은 동일하다고 해석됩니다.